
Vous êtes-vous déjà demandé comment les arnaqueurs et les personnes malveillantes faisaient en sorte d’afficher une image avec un lien sur les réseaux sociaux qui ne redirige pas vers le site légitime ?
⚠️ Disclaimer ⚠️ Je n'incite en aucun cas la reproduction de ce tutoriel à des fins malveillantes. Cet article a pour unique but d'avoir un aspect pédagogique et de comprendre comment font des acteurs malveillants afin de tromper les individus.
Dans cet article on va voir en détail cette technique avec une explication visuelle et la partie technique associée.
Si vous souhaitez accéder directement à la partie qui vous intéresse, vous pouvez utiliser le sommaire ci-dessous.
Bonne lecture !
Summary
🔗 Qu’est-ce qu’un lien ?
Même si la plupart des personnes qui liront cet article savent déjà ce qu’est un lien, il est toujours utile de revenir sur les bases afin de mettre tout le monde sur un pied d’égalité.
Avant de parler de lien, on va parler d’URL.
Une URL (Uniform Resource Locator) est une chaîne de caractères composée de différentes parties qui permet d’indiquer l’adresse d’un site, d’une page, d’une ressource.
Une URL est décomposée en plusieurs parties qui donnent chacune une information spécifique :

On pourrait croire qu’un lien est la même chose qu’une URL sauf qu’il y a une légère différence. Comme indiqué au dessus, une URL correspond à l’adresse de la ressource, tandis que le lien lui, est l’action qui permet de nous rediriger vers la ressource.
C’est pour cela qu’on parle très souvent de "lien cliquable". Le clic est l’action qui va nous rediriger vers l’URL en question.
La plupart du temps, ces deux termes sont employés de la même manière et c’est très bien comme ça, on se comprend quand même.
🔍 Qu’est-ce que la prévisualisation des liens ?
Sur la plupart des réseaux sociaux (on verra des exemples plus tard), il y a une fonctionnalité qui permet de créer des posts, de poster des messages, des images et vidéos sur son propre profil.
La prévisualisation des liens est donc une fonctionnalité de ces réseaux qui permet, lorsqu’on insère une URL dans un post, d’y ajouter automatiquement un rendu visuel qui correspond à la ressource cible.
Voici un exemple pris sur LinkedIn d’un de mes posts dans lequel j’ai inséré l’URL d’un article de mon blog (rouge). LinkedIn a automatiquement généré une prévisualisation de la page (vert) et l’a inséré dans le post.
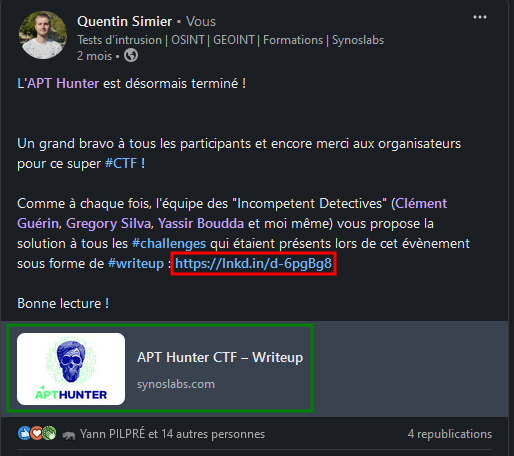
Vous remarquerez qui LinkedIn a également modifié l’URL que j’avais spécifié au départ. On n’en parlera pas forcément ici parce qu’il faudrait un autre article dédié à ce sujet mais c’est une transformation comme le font les raccourcisseurs de liens (bit.ly et autres).
Vous imaginez donc qu’un réseau social sans prévisualisation des liens est assez triste et beaucoup moins visuel. Un peu comme sur Youtube, la miniature joue un énorme rôle sur le fait d’inciter les utilisateurs à cliquer sur le lien ou non.
⚙️ Comment ça fonctionne ?
En théorie, si tout fonctionne correctement :
- On crée un post avec notre URL.
- Le réseau social va faire en sorte de créer un embed (une intégration) correspondant à la cible.
- L’utilisateur clique sur le lien généré (ou directement sur la prévisualisation).
- Il est redirigé vers la ressource en question.
Sauf qu’il est possible de tromper le réseau social afin de lui faire afficher une prévisualisation différente du site web vers lequel on va rediriger l’utilisateur ! (le meilleur pour la fin :p)
Et normalement, vous devriez me poser la question suivante : "Mais comment font les réseaux sociaux pour créer cette visualisation ?"
Et c’est une très bonne question 😀
Réponse courte : ils vont effectuer eux-même une requête sur l’URL spécifiée.
Réponse très longue :
Lorsque n’importe quelle requête HTTP/HTTPS est effectuée, il est possible d’y affecter un en-tête (header en anglais) qui va indiquer des informations sur le navigateur de celui qui effectue cette dite requête. On appelle cet en-tête un User-Agent (ou UA).
Avec les navigateurs, celui-ci est ajouté de manière transparente dans vos requêtes et vous n’avez pas besoin de vous en soucier.
Du côté des sites web, c’est souvent très pratique pour déterminer avec quel type d’appareil vous naviguez sur le site.
En effet, un User-Agent peut être vu un peu comme une signature de votre navigateur. Un UA sera différent si vous êtes sous Linux, Windows ou Mac. Mais aussi si vous êtes sous Chrome, Firefox ou Safari. Ou encore sous mobile ou desktop.
Bref, vous l’avez compris, il existe une infinité de possibilité pour les User-Agent.
Mais pourquoi je vous parle de ça ?
Eh bien c’est parce que les bots des différents réseaux sociaux qui vont récupérer les meta données de l’URL qu’on spécifie dans notre post pour ensuite créer la prévisualisation du site utilisent également les User-Agent.
Et on peut le vérifier très facilement (attention à ceux allergiques au côté technique).
Je vais me rendre sur mon serveur web sur lequel la page que je souhaite inclure dans mon post est hébergé (serveur Ubuntu avec apache2).
Je vais me rendre dans le dossier des logs qui répertorie toutes les requêtes qui sont faites vers mon site web et je me mets en écoute :
tail -F /var/log/apache2/access.logOn voit apparaître une nouvelle requête :

Si on regarde de plus près son contenu, on distingue son User-Agent qui semble commencer par LinkedInBot/1.0
Lorsque LinkedIn a voulu récupérer les informations de la page pour créer la prévisualisation, une requête a bien été effectuée vers notre page.
🎯 Manipuler la prévisualisation
Comme nous l’avons vu dans la partie précédente, chaque réseau social est obligé d’effectuer une requête vers la page en question afin de récupérer certaines données pour créer la prévisualisation.
Nous avons également vu qu’ils spécifiaient un User-Agent dans chaque requête.
Ce User-Agent est toujours identique et plusieurs sites web existent pour répertorier les UA utilisés par la plupart des gros sites :
https://explore.whatismybrowser.com/useragents/explore/software_name/
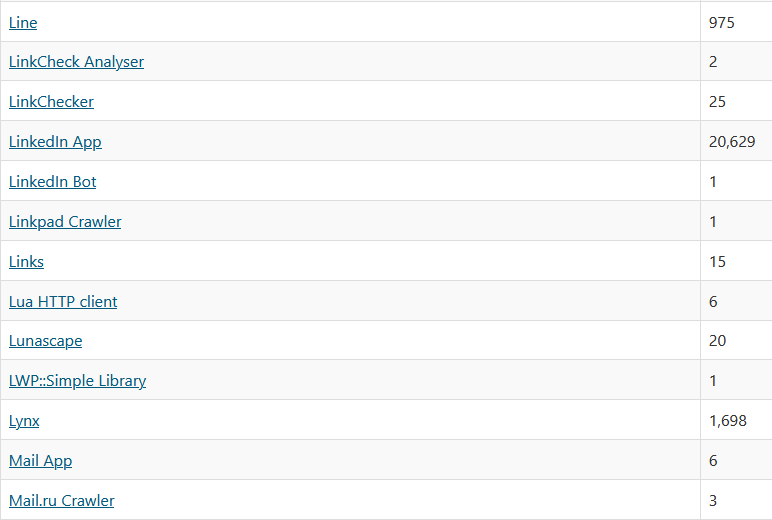
Si on reprend l’exemple de LinkedIn, on retrouve bien le même User-Agent qui avait été identifié dans les logs de notre serveur :

Dans le cas où le site web n’est pas répertorié dans ces immenses bases de données, il est toujours possible d’identifier manuellement le User-Agent comme vu dans la partie précédente.
Il est donc très facile de connaître la chaîne de caractère utilisée par chaque site web afin de créer cette fameuse prévisualisation.
Avant de vous dévoiler tous les secrets (encore ?), il faut également qu’on parle de redirection.
Comme son nom l’indique, une redirection permet de rediriger un utilisateur d’un site web vers un autre. On verra techniquement par la suite implémenter ça au niveau du code mais c’est très simple.
Un exemple de redirection serait lorsque vous vous connectez sur un site à votre espace membre. Vous allez donc sur la page de login, rentrez vos informations et validez.
Après quelques secondes, si vos informations existent et correspondent à un compte valide, alors vous êtes redirigé vers votre dashboard en tant qu’utilisateur authentifié.
Ici, lorsqu’on parle de bots qui vont effectuer les requêtes depuis les réseaux sociaux pour créer les prévisualisations, on parle évidemment d’automatisation. Mais cela ne change strictement rien au fonctionnement, c’est exactement la même chose qu’il se passe si c’était un humain qui faisait les requêtes avec ces petits doigts.
Et donc, la redirection fonctionne également sur les robots (vous commencez à voir venir ?).
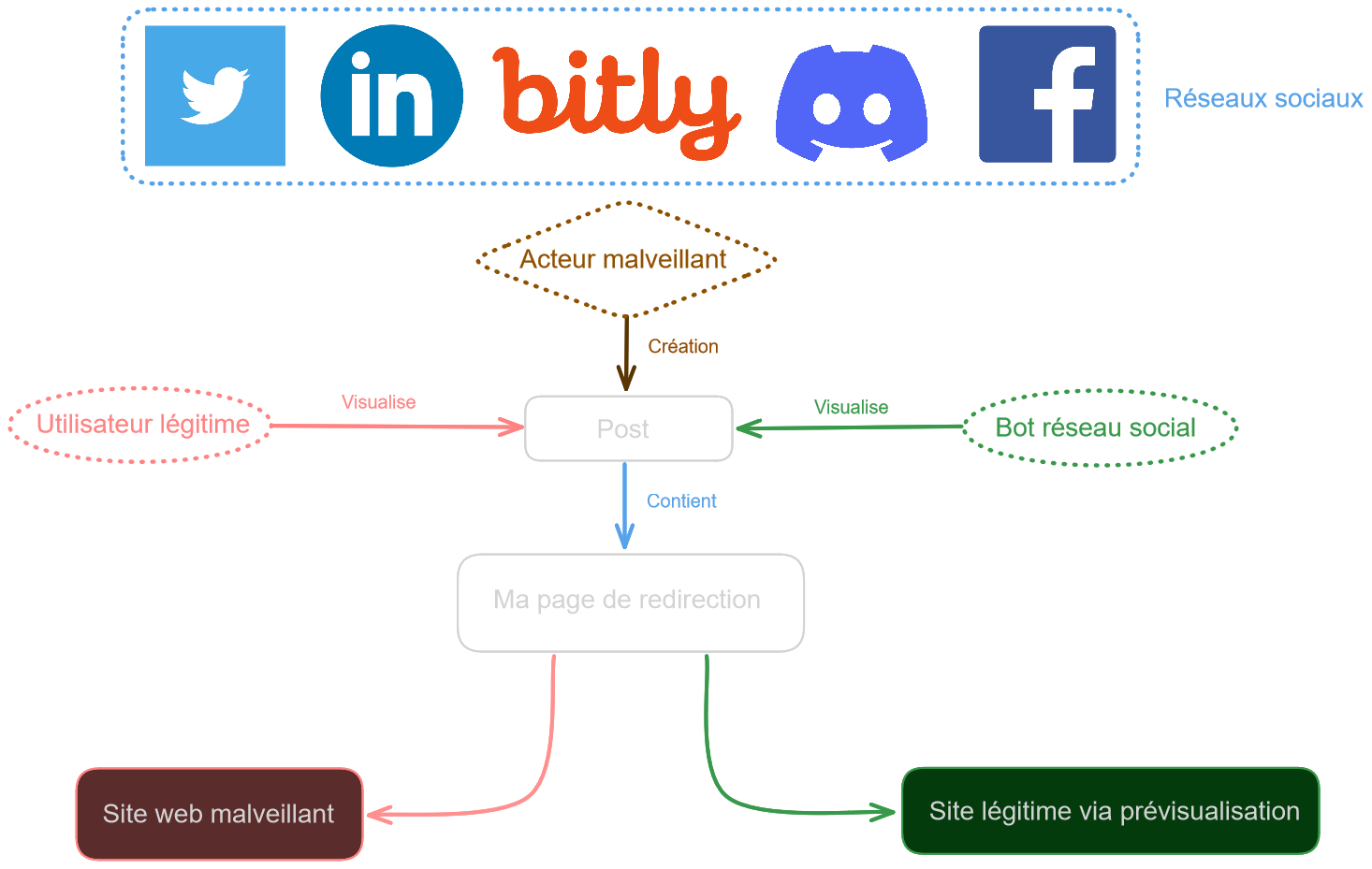
Je vous ai suffisamment fait attendre, voici comment manipuler la prévisualisation :
- Je crée une page sur mon site web qui va uniquement servir pour rediriger les utilisateurs et les robots vers d’autres pages.
- Je détecte si chaque requête entrant vient d’un humain ou d’un bot (en me basant sur le User-Agent).
- Si bot, alors je redirige celui-ci vers le site pour lequel je veux générer une prévisualisation.
- Si humain, alors je redirige vers le site sur lequel je veux le faire arriver.
Au final, la prévisualisation correspondra au site cible vers lequel j’ai redirigé le bot. Quand la personne va cliquer sur la prévisualisation, elle sera redirigée vers le site web que j’ai choisi en pensant être sur celui affiché avec la prévisualisation.
Toujours pas clair ?
Voici plusieurs exemples concrets effectués sur différentes réseaux sociaux :
Twitter :
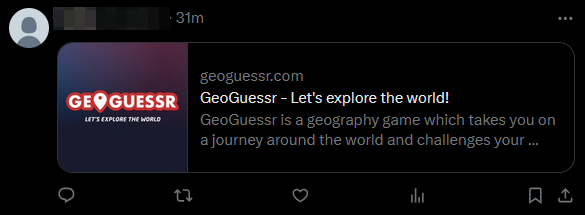
Facebook :

Bitly :

Discord :

LinkedIn :
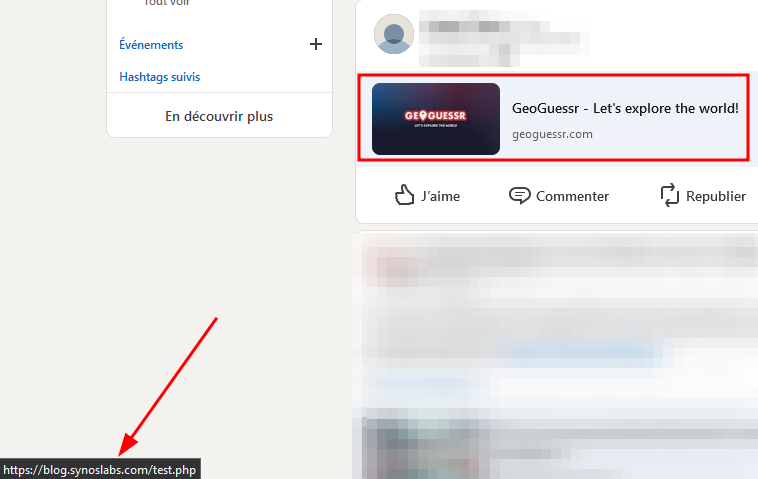
Et petit bonus avec un lien Bitly "hacké" et posté sur Discord :

A chaque fois, on voit bien que la prévisualisation affiche Geoguessr mais que le lien ne redirige en aucun cas vers le site.
En fait cette technique a un nom spécifique (je n’ai absolument rien inventé). Il s’agit du cloaking qui est souvent utilisé en SEO pour optimiser les résultats de recherche pour des sites web.
Attention cependant, cette technique n’est pas autorisée par tous les moteurs de recherche. Google considère ça comme du spam et peut donc décider de supprimer les sites utilisant cette technique des résultats du moteur de recherches :
https://developers.google.com/search/docs/essentials/spam-policies?hl=fr#cloaking
Voici un schéma qui récapitule l’attaque :
🤖 Page de redirection (PHP)
Vous avez maintenant l’idée principale de ce type de manipulation. Il suffit juste de l’implémenter avec du code pour faire en sorte de rediriger correctement les utilisateurs et robots en fonction de qui accède à la page.
Premièrement pourquoi PHP ?
Tout simplement parce que je connais le langage, il est très simple d’utilisation et s’installe facilement en même temps qu’apache ou un autre serveur web.
Vous pouvez très bien le faire dans un autre langage, ça n’a aucune importance.
Voici donc à quoi ressemble le code que j’ai écrit :
<?php
// List of all user agents to check for
$twitter_ua = "Twitterbot/1.0";
$discord_ua = "Mozilla/5.0 (compatible; Discordbot/2.0; +https://discordapp.com)";
$facebook_ua = "facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)";
$linkedin_ua = "LinkedInBot/1.0 (compatible; Mozilla/5.0; Apache-HttpClient +http://www.linkedin.com)";
$bitly_ua = "bitlybot/3.0 (+http://bit.ly/)";
// Add them into an array
$user_agents = array($twitter_ua, $discord_ua, $facebook_ua, $linkedin_ua, $bitly_ua);
// Check if User Agent is among the array
if(in_array($_SERVER['HTTP_USER_AGENT'], $user_agents)){
// If user agent detected as a bot then redirect to the website which will be integrated in the embed
header("Location: https://www.geoguessr.com/");
}
else {
// Redirect the legitimate user
header("Location: https://www.youtube.com/@krowz_?sub_confirmation=1");
}
?>J’ai inséré des commentaires mais on peut quand même revenir rapidement sur l’ensemble du code.
Au tout début, je définis un ensemble de variables avec des noms explicites pour chaque user agent de réseau social et je leur attribue la valeur du user agent associé (que j’ai trouvé sur https://explore.whatismybrowser.com/useragents/explore/software_name/ ou dans les logs de mon serveur web).
J’ajoute toutes les variables dans un tableau.
Et maintenant, tout se joue ici.
Je regarde si le user agent qui se connecte à ma page (via $_SERVER['HTTP_USER_AGENT']
Si c’est le cas alors c’est que le robot d’un des sites est arrivé sur la page et donc qu’il tente de créer la prévisualisation. Dans ce cas je le redirige vers le site web légitime pour lequel je souhaite que les informations soient affichées dans mon embed sur le réseau social.
Sinon, c’est que c’est un utilisateur lambda et je le redirige donc vers ma page malveillante (ou tout autre page vers laquelle j’ai envie de l’emmener).
➕ Bonus
On pourrait encore s’amuser longtemps en mettant des filtres personnalisés en fonction des différents user agents. Il y a une infinité de possibilités.
Pour finir, on peut voir un autre exemple assez parlant qui va rediriger sur différentes pages en fonction du navigateur utilisé par le client.
Pour cette exemple, on ne s’occupe pas de ce qui est montré au niveau de la prévisualisation mais c’est tout à fait possible de l’intégrer, comme nous l’avons fait précédemment :
<?php
if(preg_match("/edge/i", $_SERVER['HTTP_USER_AGENT'])){
header("Location: https://google.com/");
}
else if(preg_match("/firefox/i", $_SERVER['HTTP_USER_AGENT'])){
header("Location: https://synoslabs.com/");
}
else {
header("Location: https://synoslabs.com/articles");
}
?>🛡️ Comment s’en prémunir ?
Ce type de redirection n’est pas simple à analyser d’un point de vue d’un défenseur.
On peut analyser et obtenir la liste des pages par lesquelles nous sommes passées, mais on n’est jamais sûr d’avoir suivi le bon chemin.
Comment connaître toutes les routes et toutes les redirections possibles pour une page en particulier ? C’est presque impossible.
L’une des possibilités est d’avoir directement accès au code source. Mais c’est extrêmement rare.
Des outils existent comme Lookyloo mais comme indiqué juste avant, on va pouvoir analyser que le chemin emprunté par notre navigateur, pas TOUS les chemins possibles.
On pourrait tenter d’accéder à la chaîne à l’URL en essayant un user agent différent à chaque fois pour détecter si certaines redirections amènent vers d’autres sites.
Mais encore une fois, on ne peut pas être exhaustif. Surtout si la personne a une sorte de mot clé secret dans le user agent qui ferait rediriger les personnes uniquement sous certaines conditions.
On pourrait penser aussi à un autre système avec des en-têtes personnalisés ou bien certains mots clés dans des paramètres de requêtes GET.
Dans tous les cas, voici quelques pistes pour remédier (en partie) à ce problème de prévisualisation avec une redirection différente en fonction du user agent utilisé :
- Accéder aux liens avec plusieurs UA : le réseau social pourrait utiliser plusieurs user agents différents pour vérifier qu’ils mennent tous vers le même lien. Mais X fois plus long en fonction du nombre de UA utilisés. Et si ceux-ci sont connus alors on peut réutiliser la même technique que je vous ai présenté et on en revient au même problème.
- Ne pas utiliser un UA spécifique : les réseaux sociaux pourraient utiliser des user agents légitimes de navigateurs ou bien en générer aléatoirement à chaque requête pour ne pas qu’elles soient prédictibles. Cependant, j’imagine que pour des besoins de RGPD et autres lois, ils sont obligés d’indiquer qui ils sont dans les requêtes.
- Faire aller l’utilisateur sur la même page que celle du bot (solution proposée par Lexi, lien dans les ressources en bas de page) : celle solution force la redirection par le réseau social sur le même site que celui parcouru par le robot. C’est une possibilité, mais on peut toujours faire en sorte d’avoir un "proxy" sur une de nos pages web qui imite un site légitime, ou bien peut-être avec un système de timeout ?
🖊️ Bref, voici quelques idées de remédiations qui me sont venues à l’esprit comme ça, si vous avez une solution concrète et efficace ou bien même des idées pour résoudre cette problématique, n’hésitez à m’en faire par directement via ma page de contact du site ou par mail : contact <<>@>< synoslabs.com (tout attaché et sans les chevrons).
Je modifierai cet article afin d’y ajouter votre idée !
Merci d’avoir lu l’article et bonne journée / soirée à vous !
📗 Ressources
https://explore.whatismybrowser.com/useragents/explore/software_name/
https://medium.com/@l3x1/how-i-hijacked-the-url-displayed-on-twitter-link-previews-3796904eb1cb
https://twitter.com/nicolaspopy/status/1743010564903678141
https://developers.google.com/search/docs/essentials/spam-policies
https://explore.whatismybrowser.com/useragents/explore/software_name/